Your organization just invested in a process mining platform. Six months later, the dashboards are impressive — event logs visualized, variant counts tracked, bottlenecks highlighted. But when you ask the operations team why those bottlenecks exist, or what actually happens between the system events, no one can answer clearly.
The tool captured what the systems recorded. It missed how people actually work.
This is the core confusion in the process intelligence market right now. "Process discovery," "process mining," and "task mining" are used interchangeably in vendor marketing — but they describe fundamentally different approaches with different data sources, different blind spots, and different results.
Understanding the distinction matters more than it used to. As organizations invest in AI-driven automation and transformation, the quality of their process intelligence directly determines the quality of their outcomes. Building automation on incomplete or inaccurate process data is one of the most expensive mistakes a transformation team can make.
The Automated Discovery for Consulting guide covers how modern teams are rethinking their discovery infrastructure entirely — moving away from system-centric tools toward approaches that capture how work actually happens, including the human layer that event logs miss.
Process mining, task mining, and process discovery emerged from different research traditions and were built to solve different problems. But as the enterprise software market consolidated, vendors started marketing all three capabilities under unified "process intelligence" platforms — often with different names for the same thing, or the same name for different things.
Celonis built its leadership position on process mining: reconstructing workflows from ERP and CRM event logs. SAP acquired Signavio to add process modeling and management layers to that same foundation. UiPath extended into task mining as a way to identify desktop automation opportunities for its RPA platform. IBM and Microsoft have their own variants, all positioned as "comprehensive" discovery solutions.
The result: buyers evaluate these platforms without a clear picture of what each method can and cannot capture — and they build transformation strategies on an incomplete understanding of their own processes.
Process mining requires event logs — structured data records that enterprise systems write automatically as transactions occur. SAP logs purchase orders. Salesforce logs deal stage changes. ServiceNow logs ticket state transitions.
What gets logged is only what the system records. The phone call a sales rep makes to unstick a deal before it's updated in Salesforce. The manual workaround a finance analyst runs in Excel to reconcile two systems that don't integrate. The informal escalation path that bypasses the ticketing system entirely. These don't appear in event logs — which means they don't appear in process mining outputs.
For many organizations, these invisible human activities are exactly where the most important operational complexity lives.
Task mining was developed to address some of what process mining misses. It uses desktop recording and user interaction data — screen captures, keystrokes, application switching — to understand how people perform individual tasks at their computers.
This captures the human-computer interaction layer that process mining ignores. But it has significant limitations: it only sees what happens on a monitored device, it requires agents installed on employee machines (creating privacy and trust concerns), it still can't capture verbal communication, judgment calls, or cross-functional handoffs that happen outside the digital trail, and it is notoriously expensive to implement and maintain at scale.
Task mining was built for RPA opportunity identification, not for organizational process understanding. When applied to the latter, its coverage gaps create a distorted picture.
When a consultant asks a client "what is your process for onboarding a new enterprise customer?", the answer they receive is the official version — the one that aligns with the documented policy. What they rarely hear in the first conversation is the informal escalation path, the three-way spreadsheet that compensates for the CRM's limitations, or the fact that one regional team does it entirely differently.
Neither process mining nor task mining surfaces this kind of knowledge. Both approaches depend on captured data — data that only exists if the activity was logged or recorded. Knowledge that lives in people's heads, or that is transmitted informally between colleagues, is invisible to both.
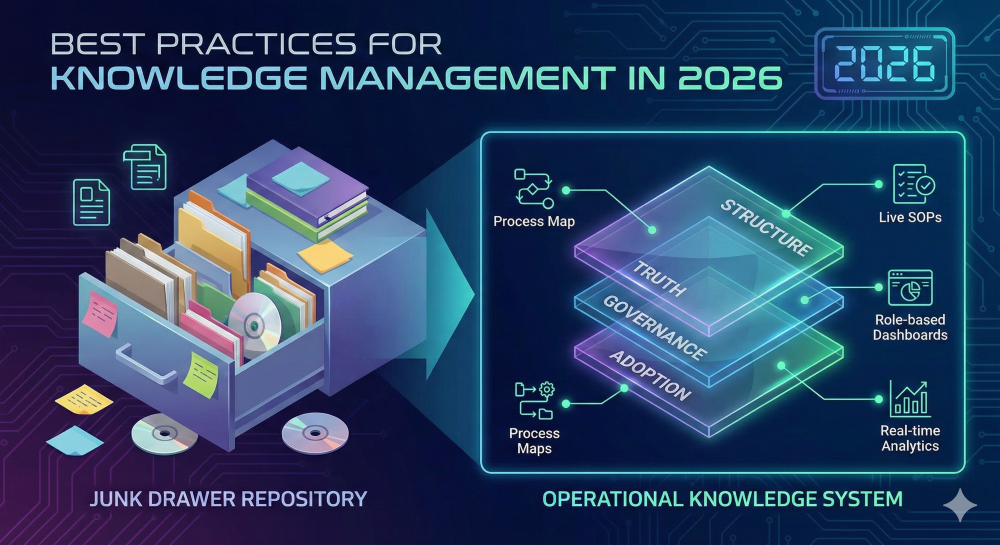
Process discovery — genuine process discovery — is the practice of capturing how work actually happens, including the human layer: the decisions, exceptions, workarounds, and informal paths that never appear in system logs.
It is not the same as process mining, which reconstructs workflows from existing system data. It is not the same as task mining, which records desktop activity on monitored machines. And it is not the same as traditional documentation — asking stakeholders to write down their processes, which consistently produces idealized descriptions rather than operational reality.
Modern process discovery uses structured, repeatable methods to surface operational truth from the people who hold it. The goal is not to validate what systems show. It is to capture what systems cannot see.
This approach applies any time an organization needs to understand work that crosses systems, teams, or informal communication channels — which is most of the work that drives operational performance and transformation outcomes.
Before choosing a method, determine what kind of process intelligence the decision requires.
If you are diagnosing throughput issues in a process that runs entirely within a single ERP system, process mining will give you clean, data-driven answers. If you are trying to understand why desktop-intensive manual tasks take longer than expected, task mining may surface useful efficiency data. If you are trying to understand how work actually moves across teams, systems, and informal channels — or if you need to capture the knowledge that experienced operators carry — you need discovery that goes beyond logged data.
Every method has a coverage boundary. Process mining covers committed database transactions. Task mining covers desktop interactions on monitored devices. Neither covers verbal decisions, informal escalations, cross-functional handoffs that don't generate system events, or the judgment calls that define process quality in complex work environments.
Map what percentage of your process lives inside those boundaries and what percentage falls outside. For transactional, high-volume, system-heavy processes, process mining coverage may be adequate. For knowledge work, consulting delivery, customer-facing operations, or any environment where informal coordination is common, the gaps are usually significant.
Process mining is the right tool for: diagnosing bottlenecks in ERP-driven workflows, identifying automation candidates in high-volume transactional processes, and tracking process conformance against a defined model.
Task mining is the right tool for: identifying specific desktop automation opportunities, measuring time-on-task for computer-based work, and supplementing process mining for steps that generate limited system event data.
AI-driven process discovery is the right tool for: understanding how work actually happens across teams and systems, capturing operational knowledge before a transformation, documenting processes that live in people's heads rather than system logs, and building accurate requirements for automation or process redesign.
Regardless of method, the output of any discovery effort should be validated by the people who do the work. Process mining outputs can be presented to operators who can identify where the event log picture diverges from reality. Task mining outputs should be reviewed with the individuals whose work was recorded. AI-discovered process maps should be reviewed by multiple stakeholders before they are used to drive decisions.
Discovery that is not validated against lived operational experience is a starting point, not a conclusion.
Days 1–7 — Scope and Method Selection Define which processes are under analysis. Map the system footprint: which systems generate event logs, which steps happen outside those systems, and which roles hold undocumented process knowledge. Choose your primary discovery method based on this mapping.
Days 8–14 — Data Collection For process mining: extract event logs and run initial discovery. For task mining: deploy monitoring agents and collect baseline interaction data. For AI-driven discovery: run structured async interviews with the operators, coordinators, and subject matter experts who hold process knowledge.
Days 15–21 — Synthesis and Gap Analysis Build the initial process picture from collected data. Identify where the data stops and where human knowledge begins. Flag the gaps — these are the sections of the process that require direct discovery rather than data extraction.
Days 22–30 — Validation and Output Present the initial process map to operational stakeholders. Capture corrections, additions, and edge cases. Produce a validated process document that reflects actual operational practice, not just what the systems recorded.
Organizations that choose their discovery method based on coverage fit rather than vendor category make better transformation investments.
Process mining on the right processes — high-volume, system-heavy, ERP-driven — delivers genuine ROI: faster bottleneck identification, conformance monitoring, and automation targeting that rests on real data. These are well-established, measurable outcomes.
The failure pattern comes when process mining is applied to processes it cannot adequately cover, and the gaps go unrecognized. Automation built on incomplete process understanding creates new failure modes. Requirements built from event logs that miss the human coordination layer produce solutions that don't reflect how work actually flows.
Organizations that use AI-driven discovery for the human layer alongside data-driven tools for the system layer consistently produce more accurate process maps, better requirements, and transformation projects that don't unravel when they encounter the informal processes that were never captured.
The compound effect is significant: faster discovery, fewer rework cycles, and a process baseline that holds up when implementation begins.
Tools like ClearWork address the part of process discovery that system-level tools cannot reach. Rather than capturing event logs or recording desktop activity, ClearWork deploys AI agents that interview the people who do the work — asynchronously, at scale, without requiring workshops or live facilitation sessions.
The output is a structured process picture grounded in what operators, coordinators, and subject matter experts actually describe — including the workarounds, exceptions, and informal paths that define operational reality but never appear in system data.
This makes ClearWork complementary to process mining and task mining rather than a replacement. When a Celonis or SAP deployment identifies a bottleneck, ClearWork can surface the human-layer explanation. When a transformation team needs to document what happens between system events, ClearWork provides the mechanism.
More on how this fits into a broader discovery workflow is covered in the Automated Discovery for Consulting guide.
Process mining reconstructs process flows from existing system event logs — data that enterprise systems like SAP, Salesforce, or ServiceNow generate automatically. Process discovery refers to the broader practice of understanding how work actually happens, which often requires going beyond logged data to capture the human layer: decisions, workarounds, informal coordination, and tacit knowledge that systems don't record.
Use process mining when the process runs primarily through enterprise systems that generate event logs, and when you need to analyze large volumes of transactions systematically. Use task mining when you need to understand desktop-level execution of specific tasks, particularly for identifying RPA automation candidates. Use AI-driven discovery when the process involves significant human coordination, knowledge work, or informal paths that don't appear in either system logs or desktop recordings.
Yes — and for most complex transformation projects, they should be. Process mining provides accurate, data-grounded analysis for the system-heavy portions of a process. AI-driven discovery captures what happens between system events. Together, they produce a more complete and accurate process picture than either method alone.
Task mining requires agents installed on monitored machines, raising privacy and change management concerns. It only captures what happens on those specific devices — it misses verbal communication, cross-functional handoffs, and any work that doesn't happen at a computer. It was designed primarily for RPA opportunity identification, which means its outputs are optimized for automation targeting rather than broad process understanding.
Process mining tools are data extraction systems — they can only analyze data that has been logged. Tacit knowledge is, by definition, not logged anywhere. It lives in the mental models, experience, and judgment of the people doing the work. Capturing it requires asking people directly, using methods that surface operational reality rather than just recording digital traces.
The category distinction is not academic. When transformation teams choose discovery methods based on what those methods can and cannot cover, they build on a more accurate process baseline — which means fewer surprises in delivery, fewer rework cycles, and automation and redesign work that actually reflects how the organization operates. Learn how ClearWork can illuminate your next project.
Enjoy our newsletter!