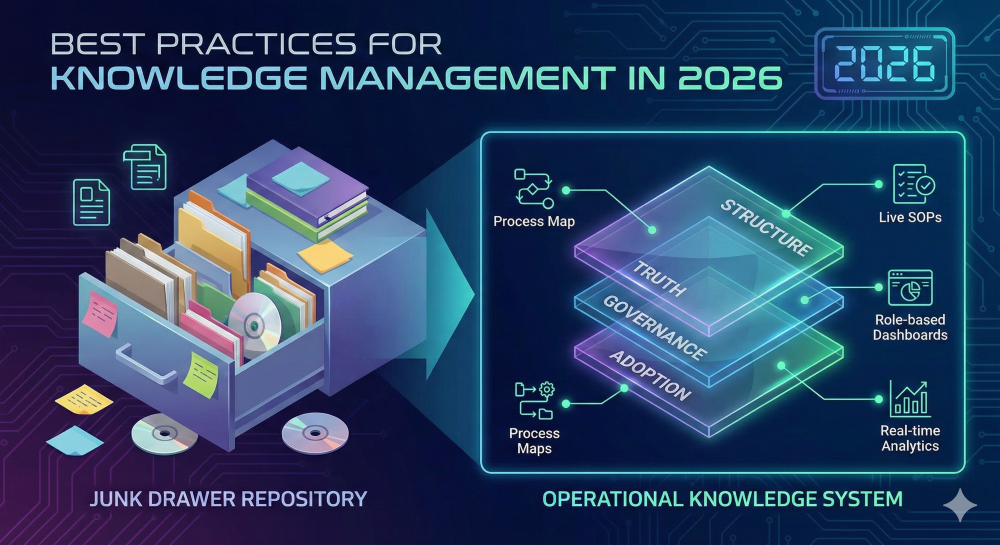
Most knowledge management programs don’t fail because the tool is bad.
They fail because the knowledge isn’t trusted, isn’t current, and isn’t owned.
So the “knowledge base” turns into what everyone secretly knows it is: a junk drawer. Duplicated SOPs. Outdated process docs. Random PDFs. “Final_v7” files. A handful of pages that are accurate, and a whole lot that aren’t. Meanwhile, the real knowledge lives in people’s heads, in Slack threads, in side spreadsheets, and in the one person everyone pings when something breaks.
In 2026, the teams who win at knowledge management stop treating it like a repository problem and start treating it like an operating system: capture → validate → publish → maintain → measure.
This post lays out a practical approach to operational knowledge management that drives adoption, reduces tribal knowledge, and turns documentation into living assets your teams actually use.
Most organizations have plenty of knowledge. They just can’t rely on it.
1) Too many sources, no single truth.
Wikis, shared drives, Confluence pages, Google Docs, Notion, email… knowledge gets duplicated and then diverges.
2) Content is written from memory, not reality.
The “official” process is captured, but exceptions, workarounds, and real handoffs don’t make it into the docs. The moment someone uses the doc and it doesn’t match what they’re seeing, trust collapses.
3) No ownership, no cadence.
If nobody is accountable for accuracy, everything drifts. And drift isn’t gradual—one system change can make ten pages wrong overnight.
4) Findability breaks as the library grows.
Tagging becomes inconsistent. Naming conventions vary. Search returns too much or nothing useful. People stop trying.
5) Knowledge isn’t connected to workflows.
Even if the knowledge exists, it’s not where people need it, when they need it—so they default to “ask someone.”
Bad KM doesn’t just feel messy. It creates real operational drag:
KM fails when it’s a place to store information. KM works when it helps people make correct decisions in the flow of work.
To build a KM program that actually gets used, you need a modern definition.
Operational KM is the practice of maintaining trusted, current, role-based knowledge about how work actually gets done:
The goal isn’t “more documentation.” The goal is usable clarity.
The biggest shift in 2026: moving from a repository mindset to living documentation.
If you want a KM program that survives beyond the kickoff, you need four layers: Truth, Structure, Governance, Adoption.
If the knowledge doesn’t reflect reality, it won’t be used.
The most reliable backbone for operational KM is process visibility:
This is why process intelligence and automatic process mapping are becoming foundational. Not because “AI is cool,” but because it creates documentation people recognize and trust.
Knowledge becomes usable when it’s structured into consistent formats.
The formats that scale:
Structure also means taxonomy:
Governance is what protects trust.
If knowledge drifts, adoption dies. So you need:
This doesn’t have to be heavy. It just has to exist.
Adoption happens when knowledge is:
If someone has to go hunting for documentation, they won’t. They’ll ping a person. Your KM system should beat “ask someone” on speed and confidence.
A common KM mistake is trying to standardize everything. That creates resistance, especially when teams know reality varies.
The principle: standardize the system, not the lived reality.
If your knowledge base is mostly random documents, you’ll always fight duplication and drift.
The most scalable approach is to anchor KM around processes and generate consistent “knowledge packs” per process.
Process documentation is reusable because it:
Random docs grow endlessly. Process-based knowledge stays organized.
For each process, publish a compact set of artifacts:
When people know “every process has the same pack,” usage goes up instantly—because the library becomes predictable.
AI can make KM dramatically better—or dramatically noisier.
The difference is governance and grounding.
The big win: AI can reduce the effort of producing knowledge packs—so SMEs spend time reviewing and correcting, not writing from scratch.
If your KM system can’t tell you what’s authoritative, it isn’t knowledge management—it’s content storage.
You don’t need a “KM council.” You need ownership and cadence.
Knowledge Owner (Accountable): responsible for accuracy and approvals
Knowledge Steward (Operational): maintains structure, versioning, cadence
SME Review Group (Consulted): validates changes and exceptions
This is enough to keep things alive.
Set cadence:
Trigger updates when:
That’s how you prevent drift without slowing everything down.
If you measure outputs, you’ll get outputs.
If you measure outcomes, you’ll get adoption.
The strongest KM teams treat metrics as a discovery tool: usage patterns tell you where knowledge is missing or untrusted.
If you want to modernize KM without turning it into a multi-quarter program:
Your goal isn’t to “document everything.” Your goal is to build a KM system people trust—then expand based on usage.
In 2026, knowledge management is less about storing documents and more about maintaining living operational knowledge that’s trusted, current, and owned. Most KM programs fail because knowledge drifts, no one is accountable for accuracy, and content isn’t structured in a way people can find and use in the flow of work.
Processes. SOPs, process maps, narratives, and decision rules create a backbone that’s reusable across onboarding, execution, audits, and transformation work. A process-based structure reduces duplication and gives teams a predictable way to find what they need.
Use lightweight governance: assign owners, set a review cadence, and define triggers that require updates (system changes, policy updates, KPI drift, repeated escalations, audit findings). The goal is to prevent drift before it erodes trust.
AI can be trusted when it’s grounded in approved sources, shows traceability, and sits behind a review and publishing workflow. Without governance, AI can spread confident wrong answers faster than humans can correct them—so versioning, approvals, and clear “official vs draft” status are essential.
Measure outcomes: faster onboarding time-to-proficiency, fewer escalations, reduced rework, higher self-serve resolution, and improved audit readiness. Pair those with leading indicators like search success rate, “zero results” queries, stale content percentage, and usage by role/process.
To see how leading organizations are taking advantage of modern tools tostreamline knowledge management, check out ClearWork's Knowledge Management Capabilities.
Most knowledge bases fail because they’re repositories, not operating systems—outdated, duplicated, and disconnected from real work. ClearWork helps teams capture how work actually happens, generate structured knowledge packs (maps, SOPs, narratives), and keep them current with lightweight governance and collaboration.
Enjoy our newsletter!