AI Agent Readiness in 2026: The Process + Requirements Foundation Agents Need to Work in the Real World
Avery Brooks
February 25, 2026
Most AI agent pilots fail for a boring reason.
Not because the model “isn’t smart enough.”
Because the workflow isn’t clear enough.
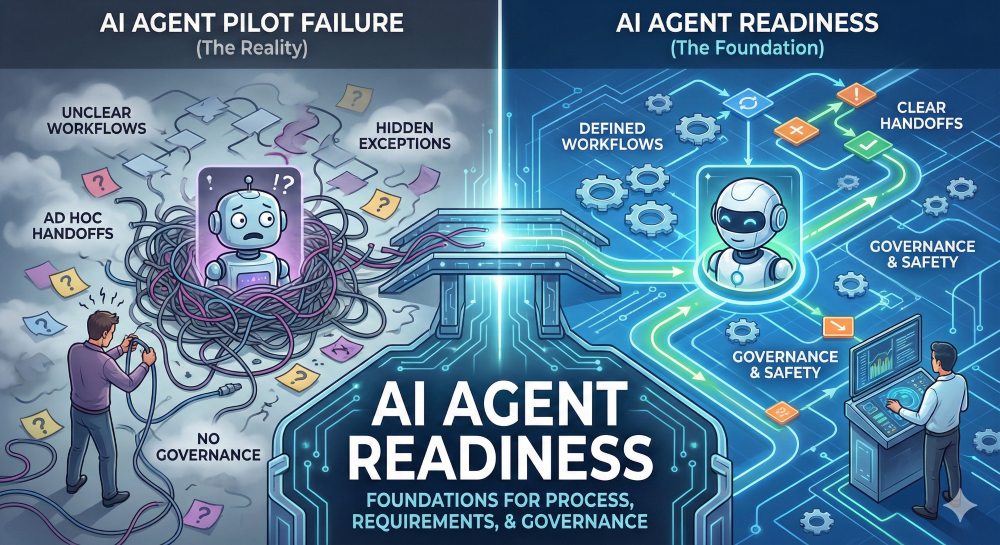
The demo looks great: the agent can summarize, respond, route, update systems, and sound confident. Then you put it into a real operational process and it hits the things every team quietly depends on:
So humans jump in to rescue the flow, and the “agent” turns into a chatbot that creates more coordination work than it removes.
In 2026, the teams getting agents into production aren’t just experimenting with tools. They’re doing AI agent readiness: making processes, requirements, exceptions, and governance explicit enough that agents can operate safely and consistently—without humans acting as constant babysitters.
This pillar post breaks down why agents fail in the real world, what readiness actually means, and a practical plan to prepare your organization for agent deployment.
Let’s start with the failure patterns. If you’ve seen one agent pilot stall, you’ve probably seen a few of these.
1) Exceptions are the norm, not the edge.
Real workflows are not a straight line. They branch constantly:
Agents that aren’t designed around exceptions will fail quickly—because exceptions are most of the work.
2) Handoffs and approvals aren’t explicit.
In many organizations, approvals happen “the usual way.”
Which means: someone pings someone, someone makes a judgment call, and the process moves forward. An agent can’t rely on tribal knowledge. It needs explicit rules and routing.
3) Inputs aren’t standardized.
Humans are great at working around missing fields. Agents aren’t—at least not safely. If the process relies on “fill in what you can and we’ll figure it out later,” you’re not agent-ready.
4) Policies exist, but they aren’t operationalized.
A policy might say “validate customer eligibility.”
But how? Based on which fields? What’s acceptable evidence? What do you do when it’s unclear? That logic needs to be made concrete.
5) No escalation path = humans take over ad hoc.
If an agent doesn’t know when to hand off, it either:
6) No auditability = risk blocks deployment.
Even when the agent works, leaders hesitate to deploy it if they can’t answer:
Agents don’t fail because they can’t “think.”
They fail because the workflow they’re stepping into is often:
If you want an agent to operate reliably, you need to make the workflow explicit—then keep it current as work evolves.
That’s what readiness is.
AI agent readiness is not a procurement exercise. It’s not “choose a model.” It’s not “install an agent platform.”
AI agent readiness is the practice of making workflows, requirements, exceptions, and governance explicit enough that an agent can operate safely and consistently—with humans only where they add value.
If you can’t clearly explain how the work happens today (including exceptions), you can’t responsibly deploy an agent to run it.
The most successful agent deployments treat readiness like an operating model: define the work → define the rules → define the controls → define who owns it.
You don’t need a hundred-page plan. You need a foundation that’s complete enough to support production behavior.
Here are the five foundations that matter.
This is where process discovery and process intelligence come in.
You need:
If the process is different depending on “who’s doing it,” the agent needs to know that. Or you need to reduce variation before automation.
Agents need more than “help with support tickets.”
They need:
Think like a delivery team: requirements aren’t a wish list, they’re a testable specification.
This is where most pilots die.
You need:
If you can’t name your top exceptions, you’re not ready. Exceptions are where operational reality lives.
This is the “we’re serious” layer.
Define:
In many workflows, safety isn’t optional. It’s the difference between a pilot and production.
Agents aren’t “set and forget.” Work changes. Policies change. Systems change.
You need:
If nobody owns the agent like a product, it will drift and get shut off.
Here’s what “ready” looks like in concrete terms.
If you can’t check these boxes, you’re not behind—you’re normal. This is the work most teams skip.
“Human-in-the-loop” is often used as a safety blanket: “We’ll have a human review it.”
But if humans are constantly reviewing, you didn’t deploy an agent—you deployed a new queue.
Humans should be in the loop when:
Humans shouldn’t be the default for:
A good handoff is structured.
Define thresholds like:
And when handing off, the agent should provide:
The goal is for the human to decide—not to re-do the work.
Not every workflow is a good first agent candidate.
Start with workflows that are:
These are the agents that actually ship.
Avoid—or fix first—workflows where:
You can deploy an agent here eventually, but it requires process work first.
The fastest wins come from reducing coordination overhead and standardizing decision logic.
If you want to move from “agent curiosity” to “agent deployment,” here’s a plan that creates real momentum.
This approach keeps pilots from turning into demos that never ship.
AI agent readiness is making workflows, requirements, exceptions, and governance explicit enough for an agent to operate safely and consistently. Most pilots fail because the process is unclear, inputs aren’t standardized, exceptions aren’t documented, and there’s no defined escalation or audit model—so humans end up rescuing the workflow.
Task automation typically handles a narrow, repeatable action. An AI agent operates across steps—making decisions, routing work, handling exceptions, and interacting with systems—so it requires clearer requirements, stronger controls, and defined governance.
At minimum: a validated process map with roles and handoffs, a list of agent actions, standardized inputs/outputs, decision rules, acceptance criteria, exception handling paths, and defined permissions/logging requirements. If you can’t test the behavior, you can’t trust it.
Define exception categories, decision rules, and explicit handoff thresholds. When an agent hands off, it should provide a structured summary of what it did, what’s missing, and the recommended next step—so the human makes a decision instead of redoing the work.
You need an accountable owner, monitoring for drift and error patterns, a change workflow that updates the agent as processes change, logging/audit trails, and rollback procedures. Agents are products, not scripts—if nobody owns them, they drift and get shut off.
Check out how ClearWork supports process transparency to help you prepare for your next agent deployment: https://www.clearwork.io/ai-agent-readiness
Agents don’t fail because they lack intelligence—they fail because the workflows they’re dropped into are undefined, inconsistent, and full of hidden exceptions. ClearWork helps teams capture how work actually happens, turn it into requirements and controls agents can follow, and keep that foundation current as work changes.