Process Documentation vs Knowledge Management: Why Most Teams Are Using the Wrong System
Avery Brooks
April 15, 2026
The onboarding takes three weeks instead of three days. A process change rolls out, and half the team is still doing it the old way two months later. A new hire asks how to handle an exception, and the answer is: "Ask Sarah — she's been here the longest."
These are knowledge problems. But the tool most organizations reach for is a knowledge management system: a wiki, a Confluence space, a Notion database. They fill it with documentation, training materials, and internal guides. And the problems persist.
The instinct is right — information needs to be captured and accessible. The mistake is assuming that a knowledge management system can do the work of process documentation. They are different systems built for different purposes, and conflating them is one of the most common and expensive operational mistakes organizations make.
This distinction — and how to fix it — sits at the core of how modern teams approach AI SOP generation and process documentation.
When an operator says "we need to document this," they might mean: write down how this process works, create training materials for new hires, capture institutional knowledge before someone leaves, build a reference guide for edge cases, or create audit-ready evidence of compliance. These are genuinely different tasks. They require different structures, different owners, and different maintenance rhythms.
Using one system — typically a knowledge base — for all of them produces a pile of content that is inconsistently structured, hard to navigate, and trusted by no one. Employees learn to work around it because they've discovered that finding a useful, current answer requires more effort than just asking a colleague.
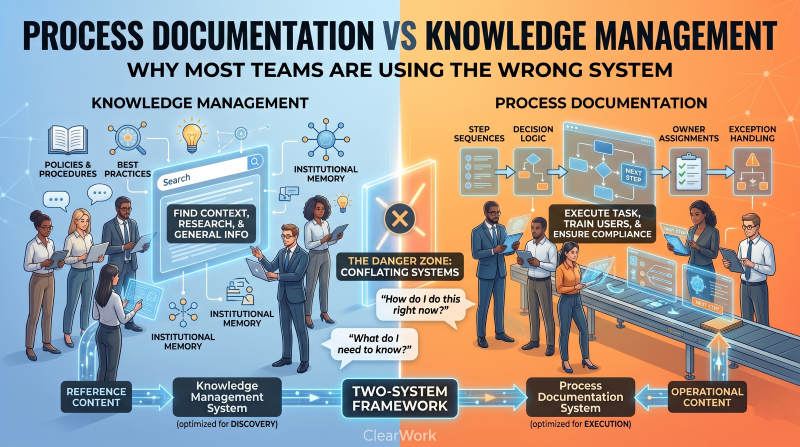
Knowledge management systems are optimized for finding and sharing information: articles, best practices, research, context. They are search-first environments. You go to them when you have a question and need to find an answer.
Process documentation serves a different function. It is execution infrastructure. You use it when you need to perform a task, train someone to perform a task, verify that a task was performed correctly, or understand why a process is designed the way it is. It is not search-first — it is workflow-first. The structure, the step sequence, the owner assignments, and the exception handling are all load-bearing in a way they are not in a knowledge article.
When process documentation gets filed into a knowledge management system, it loses that structural integrity. It becomes an article among thousands of articles, without the context signals that tell an operator "this is how you do this, right now, in this situation."
Studies consistently show that employees spend 20–30% of their time searching for information. Knowledge management systems have made this worse in many organizations, not better — by creating a single large repository where everything lives and where finding the right, current answer requires significant navigation effort.
The problem is not volume. It is structure. Process documentation needs to be findable by task, role, and context — not by keyword search. When a customer service rep is handling a return that doesn't fit the standard policy, they don't want to search a knowledge base. They need a process flow that tells them the decision logic for this exact situation.
Knowledge articles can be broadly owned — a team, a department, a subject matter expert. They get updated when someone notices they're wrong. That works reasonably well for reference information.
Process documentation requires task-level ownership. A specific process step — particularly one that touches compliance, handoffs, or exceptions — needs to have a named owner who is responsible for keeping it current when the underlying reality changes. Without that accountability structure, process documentation becomes as stale as the wiki it replaced.
When a knowledge article about company history goes stale, the consequence is minor confusion. When a process document describing a compliance step goes stale, the consequence is errors, audit findings, and operational risk. Process documentation has a much higher cost of staleness than general knowledge content — which means it requires a more rigorous maintenance model than most KM systems support.
Process documentation and knowledge management are not competing tools. They are complementary systems with distinct scopes, and understanding that distinction is the prerequisite for using either well.
Process documentation structures how work gets done: step sequences, decision logic, owner assignments, exception handling, system interactions, and compliance checkpoints. It is the operational truth of how a task is performed. It answers: "How do I do this, right now, correctly?"
Knowledge management structures what an organization knows: context, expertise, research, policies, best practices, and institutional memory. It is the accumulated learning of the organization. It answers: "What do I need to understand to operate effectively here?"
Both are necessary. Neither is a substitute for the other.
The failure mode is treating them as interchangeable — filing process instructions in the wiki alongside company history, department overviews, and random how-to articles. The process instructions decay, get buried, and stop being trusted. The wiki grows large and navigated by nobody.
Start by auditing what actually lives in your knowledge system. Classify each piece of content as either operational (needed to perform a specific task) or reference (needed to understand context, policy, or background).
Operational content belongs in a process documentation system with structured fields, owner assignments, and version history. Reference content belongs in a knowledge management system optimized for search and discovery.
Most organizations will find that 30–50% of their wiki content is actually operational — process instructions, SOPs, and workflow guides — that should not be managed as articles.
Process documentation requires specific structural elements that knowledge articles don't: the task being documented, the role responsible for each step, the systems involved, the inputs and outputs, the exception handling logic, and the compliance checkpoints. These fields are not optional — they are what makes a process document executable rather than merely informative.
If your current documentation doesn't have these fields, it is not process documentation. It is a description of a process. That distinction matters enormously when an operator is trying to act on it under time pressure.
Each documented process needs an owner — not a department, a person — who is accountable for keeping it current. When a system changes, a policy updates, or an exception reveals a gap in the existing documentation, that owner receives the trigger and is responsible for the update.
Without this, process documentation has no maintenance mechanism. It will be current on day one and wrong by month three.
Process documentation and knowledge management work best when they reference each other intentionally. A process document can link to the relevant knowledge article for context on why the process is designed this way. A knowledge article on a policy can link to the process documents that operationalize it.
This cross-referencing is what allows each system to stay in its lane. The process document tells you what to do. The knowledge article tells you why.
Pull a full list of content from your current knowledge system. Tag each item as operational or reference. Flag anything that hasn't been updated in 12 months — this is your staleness baseline. Count how many process-oriented documents exist in the system and how many have clear owner assignments.
Most teams are surprised how much of their wiki is undated, unowned process content masquerading as knowledge articles.
You don't need to migrate everything at once. Select the 10–15 most-used operational processes — the ones people ask about most, the ones new hires get wrong, the ones that generate the most clarification requests. Document these in a structured format with all required fields: owner, steps, decision logic, exceptions, systems, last reviewed date.
This is not a documentation rewrite. It is a structural reclassification. The content may already exist in the wiki — it just needs to be put in the right system with the right structure.
Define what triggers a process document review. System changes, policy updates, exception incidents, and scheduled review cycles are all valid triggers. The key is that a named person receives the trigger and is responsible for acting on it. Without this mechanism, even well-structured process documentation will decay.
Separating process documentation from knowledge management produces measurable improvements across several dimensions.
Onboarding time compresses significantly when new hires have access to structured, current, executable process documents rather than navigating a large wiki of mixed content. The 20–30% of time employees spend searching for information decreases when operational content is in a system that surfaces it by role and context, not keyword search.
Error rates drop when process documentation is structured and current. The most common source of process errors is not negligence — it is operating from stale or ambiguous documentation. When the documentation is accurate and structured, execution consistency improves.
Audit readiness improves substantially. Structured process documentation with owner assignments, version history, and review dates produces exactly the audit trail compliance teams need. A wiki with undated articles does not.
The knowledge management system also improves when it's freed from operational content. Search results become more relevant, content curation is more manageable, and the system becomes a genuine reference resource rather than a dump for everything the organization has ever written down.
The hardest part of building a proper process documentation layer is not the system choice — it is the capture problem. Capturing how work actually happens requires getting information from the people who do it, reconciling conflicting accounts, and producing structured documentation that reflects operational reality rather than idealized procedure.
Platforms like ClearWork support this by using AI-guided async interviews to capture process knowledge directly from the people doing the work. Rather than relying on documentation workshops or subject matter expert interviews that produce unstructured notes, ClearWork structures the capture process from the start — producing process documentation that is accurate, structured, and ready to be maintained over time.
The connection between capturing operational truth and maintaining it over time is explained further in ClearWork's AI SOP generation and process documentation, including how evidence-linked documentation produces a fundamentally different maintenance baseline than manually written SOPs.
Process documentation structures how work gets done — step sequences, owner assignments, decision logic, and exception handling. Knowledge management stores what an organization knows — policies, best practices, context, and institutional memory. Process documentation is execution infrastructure; knowledge management is reference infrastructure. They need different systems, different owners, and different maintenance models.
These tools can store both types of content, but they are not built to enforce the structural requirements of process documentation. Without required fields for ownership, step sequencing, and review dates, process documents filed in a wiki will be treated and maintained like wiki articles — which means they will decay. The structural discipline, not the tool choice, is what determines whether process documentation stays current.
If the document tells someone how to perform a specific task — step by step, with decision logic and owner assignments — it belongs in process documentation. If it provides context, explanation, policy background, or reference information that someone might look up to better understand their work environment, it belongs in the knowledge base. If it's trying to do both, split it.
Knowledge bases lose trust when users repeatedly find content that is outdated, inaccurate, or difficult to navigate. This is almost always a governance failure — no one owns the content, no one updates it, and no review mechanism exists. For operational content specifically, the cost of staleness is high enough that employees quickly learn to work around the documentation rather than trust it.
A basic separation — operational processes in a structured format, reference content in the knowledge base — can be established in 30 days for most organizations. The more complex work is the ongoing governance: ensuring process documents are owned, reviewed, and updated when the underlying reality changes. That typically takes 60–90 days to build as an operational habit, and ongoing attention to maintain.
The information problem most organizations face is not a shortage of documentation — it is the wrong kind of documentation in the wrong kind of system. Knowledge management systems store what the organization knows; process documentation structures how it operates. Treating them as interchangeable produces content that serves neither purpose and that employees learn to work around. Building the two systems with distinct structures, ownership models, and maintenance rhythms is what transforms documentation from an archive into operational infrastructure — and what turns the question "how does this work?" from a knowledge search into a direct, executable answer.
Fourteen days, full access, no card required. Tell us where to set you up.
No credit card required. By continuing you agree to our terms